Ученые сделали ключевой шаг к использованию формы искусственного интеллекта, известной как глубокое обучение с подкреплением, или DRL, для защиты компьютерных сетей.
При столкновении со сложными кибератаками в строгой симуляционной обстановке глубокое обучение с подкреплением эффективно не позволяло злоумышленникам достичь своих целей в 95% случаев. Результат дает надежду на роль автономного ИИ в проактивной киберзащите.
Ученые из Тихоокеанской северо-западной национальной лаборатории Министерства энергетики задокументировали свои выводы в исследовательском документе и представили свою работу 14 февраля на семинаре по ИИ для кибербезопасности во время ежегодного собрания Ассоциации по развитию искусственного интеллекта в Вашингтоне, округ Колумбия.
Отправной точкой стала разработка среды моделирования для тестирования сценариев многоэтапных атак с участием различных типов противников. Создание такой динамической среды моделирования атаки-защиты для экспериментов само по себе является победой. Среда предлагает исследователям способ сравнить эффективность различных защитных методов на основе ИИ в контролируемых условиях тестирования.
Такие инструменты необходимы для оценки эффективности алгоритмов глубокого обучения с подкреплением. Этот метод становится мощным инструментом поддержки принятия решений для экспертов по кибербезопасности — агентом защиты, способным учиться, адаптироваться к быстро меняющимся обстоятельствам и принимать решения автономно. В то время как другие формы ИИ являются стандартными для обнаружения вторжений или фильтрации спам-сообщений, глубокое обучение с подкреплением расширяет возможности защитников по организации последовательных планов принятия решений в их ежедневных столкновениях с противниками.
Глубокое обучение с подкреплением обеспечивает более эффективную кибербезопасность, возможность более раннего обнаружения изменений в киберпространстве и возможность предпринять упреждающие шаги для отражения кибератаки.
DRL: Решения в широком пространстве атаки
«Эффективный агент ИИ для кибербезопасности должен ощущать, воспринимать, действовать и адаптироваться на основе информации, которую он может собрать, и на результатах принятых им решений», — сказал Самрат Чаттерджи, специалист по данным, который представил работу команды. «Глубокое обучение с подкреплением имеет большой потенциал в этой области, где количество состояний системы и вариантов действий может быть большим».
DRL, сочетающий обучение с подкреплением и глубокое обучение, особенно хорош в ситуациях, когда необходимо принять ряд решений в сложной среде. Хорошие решения, ведущие к желаемым результатам, подкрепляются положительным вознаграждением (выраженным числовым значением); неправильный выбор, ведущий к нежелательным результатам, не поощряется за счет отрицательной стоимости.
Это похоже на то, как люди изучают многие задачи. Ребенок, который выполняет свою работу по дому, может получить положительное подкрепление в виде желаемого игрового дня; ребенок, который не выполняет свою работу, получает негативное подкрепление, например, цифровое устройство на вынос.
«Это та же концепция в обучении с подкреплением», — сказал Чаттерджи. «Агент может выбирать из набора действий. С каждым действием приходит обратная связь, хорошая или плохая, которая становится частью его памяти. Существует взаимодействие между изучением новых возможностей и использованием прошлого опыта. Цель состоит в том, чтобы создать агента, который учится принимать правильные решения».
Open AI Gym и MITRE ATT&CK
Команда использовала программный инструментарий с открытым исходным кодом, известный как Open AI Gym, в качестве основы для создания настраиваемой и контролируемой среды моделирования для оценки сильных и слабых сторон четырех алгоритмов глубокого обучения с подкреплением.
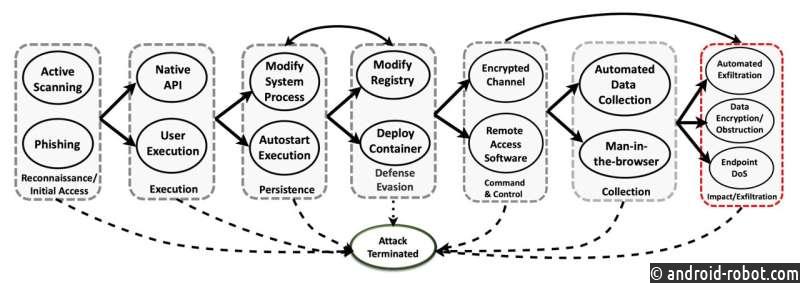
Команда использовала структуру MITRE ATT&CK, разработанную MITRE Corp., и включила семь тактик и 15 методов, развернутых тремя отдельными противниками. Защитники были оснащены 23 действиями по смягчению последствий, чтобы попытаться остановить или предотвратить развитие атаки.
Этапы атаки включали в себя тактику разведки, исполнения, настойчивости, уклонения от защиты, командования и управления, сбора и эксфильтрации (когда данные передаются из системы). Атака засчитывалась как победа противника, если он успешно достиг финальной стадии эксфильтрации.
«Наши алгоритмы работают в конкурентной среде — соревновании с намерением противника взломать систему», — сказал Чаттерджи. «Это многоэтапная атака, когда противник может использовать несколько путей атаки, которые могут меняться со временем, когда он пытается перейти от разведки к эксплуатации. Наша задача — показать, как защита, основанная на глубоком обучении с подкреплением, может остановить такую атаку».
DQN превосходит другие подходы
Команда обучала защитных агентов на основе четырех алгоритмов глубокого обучения с подкреплением : DQN (глубокая Q-сеть) и трех вариантов так называемого подхода актер-критик. Агенты были обучены с помощью смоделированных данных о кибератаках, а затем протестированы против атак, которых они не наблюдали при обучении.
DQN показал лучшие результаты.
- Наименее изощренные атаки (на основе различных уровней навыков и настойчивости злоумышленника): DQN остановил 79 процентов атак на полпути к стадиям атаки и 93 процента к финальной стадии.
- Умеренно сложные атаки: DQN остановил 82 процента атак на полпути и 95 процентов к финальной стадии.
- Самые сложные атаки: DQN остановил 57% атак на полпути и 84% к финальной стадии — намного больше, чем три других алгоритма.
«Наша цель — создать автономного агента защиты, который может узнать о наиболее вероятном следующем шаге противника, спланировать его и затем отреагировать наилучшим образом для защиты системы», — сказал Чаттерджи.
Несмотря на прогресс, никто не готов полностью доверить киберзащиту системе ИИ. Вместо этого система кибербезопасности на основе DRL должна работать совместно с людьми, сказал соавтор Арнаб Бхаттачарья, ранее работавший в PNNL.
«ИИ может быть хорош в защите от конкретной стратегии, но не так хорош в понимании всех подходов, которые может использовать противник», — сказал Бхаттачарья. «Мы далеки от той стадии, когда ИИ сможет заменить людей-кибераналитиков. Человеческая обратная связь и руководство важны».