Запуск ChatGPT от OpenAI с его удивительно связными ответами на вопросы или подсказки катапультировал модели больших языков (LLM) и их возможности в общественное сознание. Заголовки отражали как волнение, так и повод для беспокойства: можно ли написать сопроводительное письмо? Разрешить людям общаться на новом языке? Помочь ученикам списать на тесте? Влиять на избирателей через социальные сети? Лишить писателей работы?
Теперь, когда аналогичные модели появляются в Google, Meta и других компаниях, исследователи призывают к усилению контроля.
«Нам нужен новый уровень инфраструктуры и инструментов для защиты этих моделей», — говорит Эрик Энтони Митчелл, аспирант четвертого курса компьютерных наук Стэнфордского университета, имеющий докторскую степень. исследования сосредоточены на разработке такой инфраструктуры.
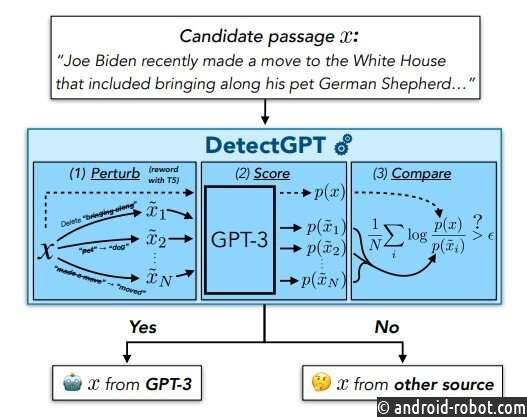
Одно из ключевых ограждений предоставит учителям, журналистам и гражданам способ узнать, когда они читают текст, созданный LLM, а не человеком. С этой целью Митчелл и его коллеги разработали DetectGPT, выпущенный на прошлой неделе в виде демонстрации и документа, который различает текст, сгенерированный человеком, и текст, созданный LLM. В первоначальных экспериментах инструмент точно определяет авторство в 95% случаев в пяти популярных LLM с открытым исходным кодом.
Пока инструмент находится на ранней стадии, Митчелл надеется улучшить его до такой степени, что он сможет принести пользу обществу.
«Исследования и развертывание этих языковых моделей продвигаются быстро», — говорит Челси Финн, доцент компьютерных наук и электротехники в Стэнфордском университете и один из советников Митчелла. «Широкой публике нужно больше инструментов, чтобы знать, когда мы читаем текст, сгенерированный моделью».
Предугадывание
Всего два месяца назад его коллега-аспирант и соавтор Александр Хазацкий написал Митчеллу СМС-сообщение с вопросом: как вы думаете, есть ли способ классифицировать, было ли эссе написано ChatGPT? Это заставило Митчелла задуматься.
Исследователи уже опробовали несколько общих подходов к смешанному эффекту. Один из подходов, используемый самим OpenAI, включает в себя обучение модели текстом, сгенерированным как человеком, так и LLM, а затем ее просят классифицировать, был ли другой текст написан человеком или LLM. Но, по мнению Митчелла, чтобы быть успешным в нескольких предметных областях и на разных языках, этот подход потребует огромного количества данных для обучения.
Второй существующий подход позволяет избежать обучения новой модели и просто использует LLM, который, вероятно, сгенерировал текст, для обнаружения собственных выходных данных. По сути, этот подход спрашивает LLM, насколько ему «нравится» образец текста, говорит Митчелл. И под «нравится» он не имеет в виду, что это разумная модель, у которой есть предпочтения. Скорее, модель «приязнь» к фрагменту текста — это сокращенный способ сказать «высокая оценка», и она включает в себя одно число: вероятность того, что эта конкретная последовательность слов появится вместе в соответствии с моделью. «Если ему это очень нравится, это, вероятно, от модели. Если нет, это не от модели». И этот подход работает достаточно хорошо, говорит Митчелл. «Это намного лучше, чем случайное угадывание».
Но когда Митчелл обдумывал вопрос Хазацкого, у него возникла первоначальная интуиция, что, поскольку даже могущественные LLM имеют тонкие, произвольные предубеждения для использования одной формулировки идеи вместо другой, LLM будет склонен «любить» любую легкую перефразировку своих собственных результатов меньше, чем LLM. оригинал. Напротив, даже когда LLM «лайкает» фрагмент текста, созданного человеком, что означает, что он дает ему высокую оценку вероятности, оценка модели слегка измененных версий этого текста будет гораздо более разнообразной. «Если мы исказим текст, созданный человеком, вероятность того, что модели он понравится больше или меньше оригинала, примерно одинакова».
Митчелл также понял, что его интуицию можно проверить с помощью популярных моделей с открытым исходным кодом, в том числе доступных через API OpenAI. «Вычисление того, насколько модели нравится конкретный фрагмент текста, — это, по сути, то, как эти модели обучаются», — говорит Митчелл. «Они дают нам этот номер автоматически, что оказывается очень полезным».
Проверка интуиции
Чтобы проверить идею Митчелла, он и его коллеги провели эксперименты, в ходе которых они оценили, насколько различным общедоступным LLM нравится текст, сгенерированный людьми, а также их собственный текст, сгенерированный LLM, включая фальшивые новостные статьи, творческие письма и академические эссе. Они также оценили, насколько LLM в среднем понравились 100 искажений каждого текста, созданного LLM и человеком. Когда команда построила график разницы между этими двумя числами для LLM-по сравнению с текстами, сгенерированными людьми, они увидели две кривые нормального распределения, которые едва перекрывались. «Мы можем очень хорошо различать источник текстов, используя это единственное число», — говорит Митчелл. «Мы получаем гораздо более надежный результат по сравнению с методами, которые просто измеряют, насколько модели нравится исходный текст».
В первоначальных экспериментах команды DetectGPT успешно классифицировал текст, созданный человеком, и текст, созданный LLM, в 95% случаев при использовании GPT3-NeoX, мощного варианта моделей GPT OpenAI с открытым исходным кодом. DetectGPT также был способен обнаруживать текст, сгенерированный человеком, и текст, созданный LLM, с использованием LLM, отличных от исходной исходной модели, но с несколько меньшей достоверностью. (На данный момент ChatGPT недоступен для прямого тестирования.)
Больше интереса к обнаружению
Другие организации также ищут способы идентифицировать текст, написанный ИИ. Фактически, OpenAI выпустила свой новый классификатор текста на прошлой неделе и сообщает, что он правильно идентифицирует текст, написанный ИИ, в 26% случаев и неправильно классифицирует написанный человеком текст как написанный ИИ в 9% случаев.
Митчелл не хочет напрямую сравнивать результаты OpenAI с результатами DetectGPT, потому что нет стандартизированного набора данных для оценки. Но его команда провела несколько экспериментов с использованием предварительно обученного ИИ-детектора OpenAI предыдущего поколения и обнаружила, что он хорошо работает с новостными статьями на английском языке, плохо работает со статьями в PubMed и полностью терпит неудачу с новостными статьями на немецком языке. По его словам, такие смешанные результаты характерны для моделей, которые зависят от предварительной подготовки. В отличие от этого, DetectGPT работал из коробки для всех трех этих доменов.
Уклонение от обнаружения
Митчелл говорит, что хотя демо-версия DetectGPT находится в открытом доступе всего около недели, отзывы уже помогли выявить некоторые уязвимости. Например, человек может стратегически разработать приглашение ChatGPT, чтобы избежать обнаружения, например, попросив LLM говорить идиосинкразически или так, как кажется более человечным. У команды есть несколько идей, как смягчить эту проблему, но они еще не проверялись.
Еще одна проблема заключается в том, что студенты, использующие LLM, такие как ChatGPT, для обмана при выполнении заданий, будут просто редактировать сгенерированный ИИ текст, чтобы избежать обнаружения. Митчелл и его команда исследовали эту возможность в своей работе и обнаружили, что, несмотря на снижение качества обнаружения отредактированных эссе, система по-прежнему неплохо справляется с обнаружением машинно-генерируемого текста, когда менее 10–15 % слова были изменены.
В долгосрочной перспективе, говорит Митчелл, цель состоит в том, чтобы предоставить общественности надежный и действенный прогноз относительно того, был ли текст или даже его часть сгенерирован машиной. «Даже если модель не думает, что все эссе или новостная статья были написаны машиной, вам понадобится инструмент, который может выделить абзац или предложение, которые выглядят особенно машинно созданными», — говорит он.
Чтобы было ясно, Митчелл считает, что существует множество законных вариантов использования LLM в образовании, журналистике и других сферах. Однако, по его словам, «предоставление учителям, читателям новостей и обществу в целом инструментов для проверки источника информации, которую они потребляют, всегда было полезным и остается таковым даже в эпоху ИИ».
Строительные ограждения для LLM
DetectGPT — лишь одно из нескольких ограждений, которые Митчелл создает для LLM. В прошлом году он также опубликовал несколько подходов к редактированию LLM, а также стратегию под названием «самоуничтожающиеся модели», которая отключает LLM, когда кто-то пытается использовать его в гнусных целях.
Прежде чем защитить докторскую диссертацию, Митчелл надеется усовершенствовать каждую из этих стратегий хотя бы еще раз. Но прямо сейчас Митчелл благодарен за интуицию, которая у него была в декабре. «В науке редко бывает, чтобы ваша первая идея работала так же хорошо, как DetectGPT. Я рад признать, что нам немного повезло».