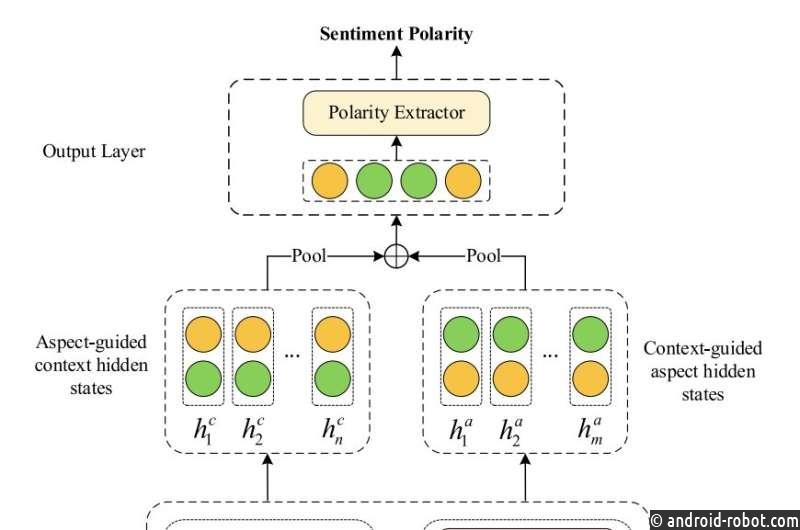
Модель для автоматического определения полярности настроений определенных слов в письменных текстах.
В последние годы ученые-компьютерщики пытались разработать эффективные модели для анализа настроений. Эти модели предназначены для анализа предложений или более длинных текстов и автономного определения лежащего в их основе эмоционального тона.
Помимо выражения общего эмоционального тона, тексты могут содержать отдельные слова, заряженные положительными или отрицательными эмоциями , а также нейтральные слова. Например, если мы на что-то жалуемся, слово, описывающее рассматриваемую вещь, скорее всего, будет заряжено отрицательной эмоцией.
Задача определения « полярности настроений » (т. е. отрицательных или положительных эмоциональных коннотаций) конкретных слов в предложении известна как аспектно-ориентированный анализ настроений (ABSA). В то время как эта задача может быть интуитивно понятной и простой для человека, решить ее с помощью вычислительных моделей может быть гораздо сложнее.
Исследователи из Аньхойского университета науки и технологии в Китае недавно разработали новую модель, предназначенную для эффективного выполнения задач ABSA. Эта модель, представленная в статье в Connection Science , основана на алгоритме машинного обучения, известном как облегченная многослойная интерактивная сеть внимания (LMIAN).
«Существующие исследования признали ценность интерактивного обучения в ABSA и разработали различные методы для точного моделирования аспектных слов и их контекстов посредством интерактивного обучения», — написали Вэньцзюнь Чжэн, Шуньсян Чжан и их коллеги в своей статье. «Однако эти методы в основном используют неглубокий интерактивный способ моделирования аспектных слов и их контекстов, что может привести к отсутствию сложной информации о тонах. Чтобы решить эту проблему, мы предлагаем Облегченную многослойную интерактивную сеть внимания (LMIAN) для ABSA».
Интерактивные сети внимания могут научиться обращать внимание на определенные слова в предложении с помощью механизма внимания, который позволяет им связать эти слова с общим лингвистическим контекстом, в котором они встречаются. В рамках своего недавнего исследования Чжэн, Чжан и их коллеги обучили одну из этих моделей специально изучать сложную эмоциональную информацию, скрытую в тексте, чтобы затем определить полярность настроений конкретных слов.
«Сначала мы используем предварительно обученную языковую модель для инициализации векторов встраивания слов», — написали Чжэн, Чжан и их коллеги в своей статье. «Во-вторых, интерактивный вычислительный слой предназначен для построения корреляций между аспектными словами и их контекстами. Такая степень корреляции рассчитывается несколькими вычислительными слоями с моделями нейронного внимания. В-третьих, мы используем стратегию совместного использования параметров между вычислительными слоями. модель для изучения сложных функций тональности с меньшими затратами памяти».
Исследователи обучили и оценили свою модель, используя шесть общедоступных наборов данных анализа настроений, содержащих тексты на китайском и английском языках. Эти тексты, по сути, представляют собой онлайн-обзоры продуктов или услуг со связанным объектом и меткой настроения (т. е. положительным, отрицательным или нейтральным), что в конечном итоге позволило команде обучить свою модель.
При первоначальных оценках этих наборов данных LMIAN команды добился многообещающих результатов, определяя полярность тональности слов в предложениях с точностью более 90%, при этом потребляя меньше памяти графического процессора, чем другие сети. В будущем его производительность может быть улучшена, и он потенциально может быть интегрирован с другими инструментами анализа текста и тональности.
«Обширные эксперименты доказали, что наш LMIAN обеспечивает лучший баланс между производительностью модели, размером и потреблением памяти графическим процессором», — заключили Чжэн, Чжан и их коллеги в своей статье. «В будущем мы еще больше оптимизируем нашу интерактивную модель внимания , чтобы повысить производительность и снизить потребление памяти графическим процессором. Одна из наших идей состоит в том, чтобы выполнить глубокое взаимодействие локальных функций с аспектными словами, чтобы улучшить производительность модели за счет уменьшения информации о помехах».