Дипфейки — это изображения и видео, которые объединяют смешанный исходный материал для получения синтетического результата. Их использование варьируется от тривиального до злонамеренного, поэтому ищутся методы их обнаружения, причем новейшие методы часто основаны на сетях, обученных с использованием пар исходных и синтезированных изображений. Новый метод бросает вызов этому соглашению, обучая алгоритмы с использованием новых синтезированных изображений, созданных уникальным способом. Эти новые обучающие данные, известные как изображения с автоматическим смешиванием, могут явно улучшить алгоритмы, предназначенные для обнаружения дипфейковых изображений и видео.
Увидеть значит поверить, так говорят. Однако с появлением записанных визуальных носителей всегда находились те, кто стремится обмануть. Вещи варьируются от тривиальных, таких как поддельные фильмы об НЛО, до гораздо более серьезных вещей, таких как стирание политических деятелей с официальных фотографий. Дипфейки — это всего лишь последняя новинка в длинной череде методов манипулирования, и их способность выдавать себя за убедительную реальность намного опережает развитие инструментов для их обнаружения.
Доцент Тосихико Ямасаки и аспирантка Каэдэ Сиохара из Лаборатории компьютерного зрения и медиа Токийского университета , среди прочего, исследуют уязвимости, связанные с искусственным интеллектом . Проблема дипфейков заинтересовала их, и они решили изучить способы улучшения обнаружения синтетического контента.
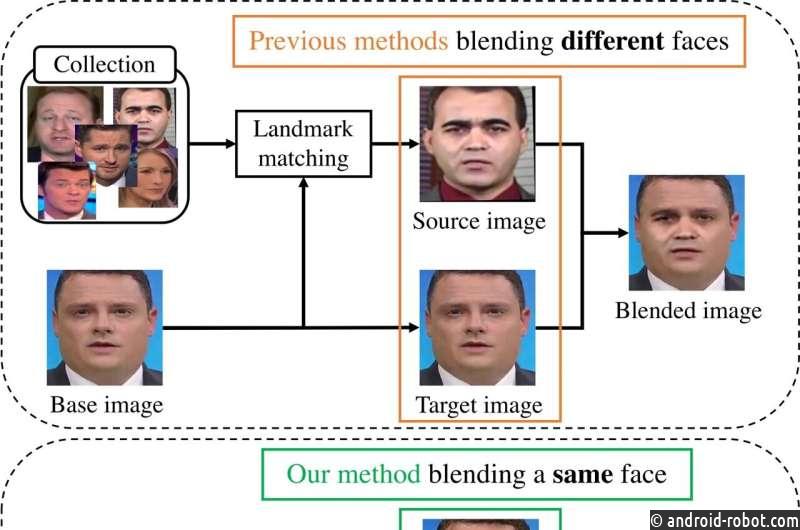
«Существует множество различных методов обнаружения дипфейков, а также различные наборы обучающих данных, которые можно использовать для разработки новых», — сказал Ямасаки. «Проблема заключается в том, что существующие методы обнаружения, как правило, хорошо работают в рамках тренировочного набора, но хуже при работе с несколькими наборами данных или, что более важно, при сопоставлении с современными примерами из реального мира. для улучшения успешных обнаружений может потребоваться переосмысление того, как используются обучающие данные. Это привело к тому, что мы разработали то, что мы называем самосмешивающимися изображениями (также известными как SBI)».
Типичные обучающие данные для обнаружения дипфейков состоят из пар изображений, состоящих из исходного изображения без манипуляций и поддельного дублирующего изображения, например, где чье-то лицо или все тело были заменены чьим-то другим. Обучение с такими данными ограничивало обнаружение определенных видов визуального искажения или артефактов, возникающих в результате манипуляций, но пропускало другие. Поэтому они экспериментировали с обучающими наборами, состоящими из синтезированных изображений. Таким образом, они могли контролировать типы артефактов, содержащихся в обучающих изображениях, что, в свою очередь, могло лучше обучать алгоритмы обнаружения для поиска таких артефактов.
«По сути, мы взяли чистые исходные изображения людей из установленных наборов данных и добавили различные тонкие артефакты, возникающие, например, в результате изменения размера или формы изображения», — сказал Ямасаки. «Затем мы смешали это изображение с исходным неизмененным источником. Процесс смешивания этих изображений также будет зависеть от характеристик исходного изображения — в основном будет создана маска, чтобы только определенные части обработанного изображения попали в смешанный выход. … Многие SBI были скомпилированы в наш модифицированный набор данных, который мы затем использовали для обучения детекторов».
Команда обнаружила, что модифицированные наборы данных улучшили точность обнаружения примерно на 5–12%, в зависимости от исходного набора данных, с которым они сравнивались. Это может показаться не таким уж значительным улучшением, но это может иметь значение между тем, кто со злым умыслом преуспевает или не может каким-то образом повлиять на свою целевую аудиторию.
«Естественно, мы хотели бы улучшить эту идею. В настоящее время она лучше всего работает на неподвижных изображениях, но видео могут иметь временные артефакты, которые мы пока не можем обнаружить. Кроме того, дипфейки обычно синтезируются лишь частично. изображения тоже», — сказал Ямасаки. «Однако я предполагаю, что в ближайшем будущем такого рода исследования могут распространиться на платформы социальных сетей и других поставщиков услуг, чтобы они могли лучше помечать потенциально манипулируемые изображения каким-то предупреждением».




