Визуальное распознавание мест (VPR) — это задача определения места, где были сделаны определенные изображения. Ученые-компьютерщики недавно разработали различные алгоритмы глубокого обучения, которые могут эффективно решать эту задачу, сообщая пользователям, где в известной среде было захвачено изображение.
Группа исследователей из Делфтского технологического университета (TU Delft) недавно представила новый подход к повышению производительности алгоритмов глубокого обучения для приложений VPR. Предлагаемый ими метод, изложенный в статье IEEE Transactions on Robotics, основан на новой модели, получившей название непрерывной регрессии дескрипторов места (CoPR).
«Наше исследование возникло из размышлений об основных узких местах в производительности VPR и связанных с ними подходах к визуальной локализации», — сказал Мубариз Заффар, первый автор исследования, Tech Xplore.
«Во-первых, мы говорили о проблеме «перцептивного наложения», т. е. отдельных областей с похожим внешним видом. В качестве простого примера представьте, что мы собираем эталонные изображения с транспортным средством, движущимся по крайней правой полосе шоссе. на крайней левой полосе того же шоссе наиболее точной оценкой VPR будет совпадение с этими соседними эталонными изображениями. Однако визуальное содержимое может неправильно соответствовать другому участку шоссе, где эталонные изображения также были собраны на крайней левой полосе».
Одним из возможных способов преодоления этого ограничения подходов VPR, выявленного Заффаром и его коллегами, может быть обучение так называемого средства извлечения дескрипторов изображений (т. е. компонента моделей VPR, извлекающего описательные элементы из изображений) для анализа изображений аналогичным образом независимо от управляющего фактора. полосе, в которой они находятся. Однако это уменьшит их способность эффективно определять место, где был сделан снимок.
«Поэтому мы задались вопросом: возможен ли VPR только в том случае, если мы собираем изображения на всех полосах для каждого нанесенного на карту шоссе или если мы едем только по одной и той же полосе? Мы хотели расширить простую, но эффективную парадигму поиска изображений VPR для решения таких практических задач», — Заффар. сказал.
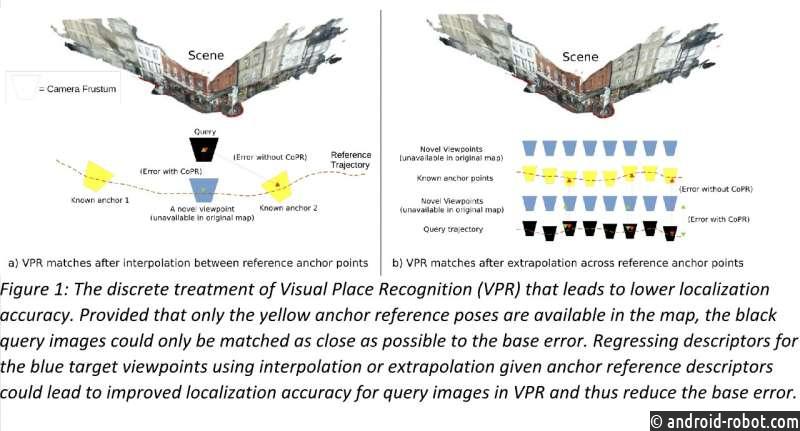
«Во-вторых, мы поняли, что даже оценка позы идеальной системы VPR будет ограничена по точности, поскольку конечный размер эталонных изображений и их поз означал, что карта не может содержать эталон с точно такой же позой для каждого возможного запроса. Поэтому мы посчитали, что, возможно, важнее устранить эту разреженность, чем пытаться создать еще лучшие дескрипторы VPR».
Изучая предыдущую литературу, Заффар и его коллеги также поняли, что модели VPR часто используются как часть более крупной системы. Например, методы визуальной одновременной локализации и картирования (SLAM) могут извлечь выгоду из подходов VPR для обнаружения так называемых замыканий петли, в то время как подходы к локализации от грубого к точному могут обеспечить точность локализации менее метра за счет уточнения грубых оценок положения VPR.
«По сравнению с этими более сложными системами шаг VPR хорошо масштабируется для больших сред и прост в реализации, но его оценка позы не так точна, поскольку он может возвращать только позы ранее просмотренных изображений, которые лучше всего визуально соответствуют запросу», — сказал Заффар.
«Тем не менее, SLAM и оценка относительной позы обеспечивают очень точную оценку позы с использованием тех же разреженных эталонных изображений и поз, так чем же эти подходы принципиально отличаются от VPR? поза к визуальным характеристикам, позволяющая рассуждать о визуальном содержании в позах, интерполированных и экстраполированных из данных ссылок».
Основываясь на своих наблюдениях, исследователи решили выяснить, могут ли те же непрерывные представления, полученные с помощью SLAM, и подходы к оценке относительной позы быть распространены на модели VPR, работающие отдельно. Традиционные подходы VPR работают путем преобразования изображения запроса в единый так называемый вектор дескриптора и последующего сравнения его с предварительно вычисленными дескрипторами, в то время как подходы к локализации от грубого к точному могут достичь точности локализации менее метра за счет уточнения грубых оценок положения VPR. В совокупности все эти ссылочные дескрипторы называются «картой».
После сравнения этих дескрипторов модель определяет, какой ссылочный дескриптор наиболее точно соответствует дескриптору изображения запроса. Таким образом, модель решает задачу VPR, разделяя местоположение и ориентацию (т. е. позу) эталонного дескриптора, наиболее похожего на дескриптор изображения запроса.
Чтобы улучшить локализацию VPR, Заффар и его коллеги просто уплотнили общую «карту» дескрипторов, используя модели глубокого обучения. Вместо того, чтобы думать об дескрипторах эталонных изображений как о дискретном наборе, отдельном от их поз, их метод по существу рассматривает эталоны как точки лежащей в основе непрерывной функции, которая связывает позы с их дескрипторами.
«Если вы думаете о паре ссылок с двумя соседними позами (то есть изображения с несколько разными местоположениями и ориентациями, но все еще смотрящими на одну и ту же сцену), вы можете представить, что дескрипторы в чем-то похожи, поскольку они представляют похожий визуальный контент». Объяснил соавтор исследования Джулиан Койдж.
«Тем не менее, они также несколько отличаются, поскольку представляют разные точки зрения. Хотя было бы сложно вручную определить, как именно изменяются дескрипторы, это можно узнать из редко доступных эталонных дескрипторов с известными позами. В этом суть нашего подхода. : мы можем смоделировать, как дескрипторы изображения изменяются в зависимости от изменения позы, и использовать это для уплотнения эталонной карты.На автономном этапе мы подбираем функцию интерполяции и экстраполяции, которая может регрессировать дескриптор в невидимой позе из близлежащей известной ссылочные дескрипторы».
После выполнения этих шагов команда может уплотнить карту, учитываемую моделями VPR, добавив регрессивные дескрипторы для новых поз, которые представляют ту же сцену на эталонных изображениях, но слегка перемещены или повернуты. Примечательно, что подход, разработанный Заффаром и его коллегами, не требует каких-либо изменений в конструкции моделей VPR и позволяет им работать в режиме онлайн, поскольку моделям предлагается больший набор ссылок, с которыми они могут сопоставить изображение запроса. Еще одно преимущество этого нового подхода к VPR заключается в том, что он требует относительно минимальной вычислительной мощности.
«Некоторые другие недавние работы (например, поля нейронного излучения и многоракурсное стерео) следовали аналогичному мыслительному процессу, также пытаясь уплотнить карту без сбора дополнительных эталонных изображений», — сказал Заффар. «В этих работах предлагается неявно/явно построить текстурированную трехмерную модель окружающей среды для синтеза эталонных изображений в новых позах, а затем уплотнить карту путем извлечения дескрипторов изображений этих синтетических эталонных изображений. Этот подход имеет параллели с трехмерными облаками точек. оценивается с помощью визуального SLAM и требует тщательной настройки и дорогостоящей оптимизации. Кроме того, результирующий дескриптор VPR может включать в себя условия внешнего вида (погода, сезоны и т. д.), которые считаются несущественными для VPR или чрезмерно чувствительными к случайным артефактам реконструкции».
По сравнению с предыдущими подходами, направленными на повышение производительности моделей VPR путем реконструкции сцены в пространстве изображения, подход Заффара исключает это промежуточное пространство изображения, что увеличивает его вычислительную нагрузку и вводит ненужные детали. По сути, вместо того, чтобы реконструировать эти изображения, подход группы работает непосредственно с эталонными дескрипторами. Это значительно упрощает крупномасштабное внедрение моделей VPR.
«Кроме того, наш подход не требует доступа к самим эталонным изображениям, ему нужны только эталонные дескрипторы и позы», — сказал Койдж. «Интересно, что наши эксперименты показывают, что подход регрессии дескрипторов наиболее эффективен, если метод VPR, основанный на глубоком обучении, был обучен с потерей, которая взвешивает совпадения дескрипторов на сходстве позы, поскольку это помогает выровнять пространство дескриптора с геометрией визуальной информации».
В первоначальных оценках метод исследователей дал очень многообещающие результаты, несмотря на простоту используемых моделей, а это означает, что более сложные модели вскоре могут достичь лучших результатов. Кроме того, было обнаружено, что этот метод имеет очень похожую цель с существующими методами оценки относительной позы (т. е. для предсказания того, как сцены трансформируются при взгляде на них под определенным углом).
«Оба подхода направлены на устранение различных типов ошибок VPR и дополняют друг друга», — сказал Коой. «Оценка относительной позы может дополнительно уменьшить количество ошибок конечной позы из правильно полученного эталона с помощью VPR, но она не может исправить позу, если VPR неправильно извлекла неправильное место с внешним видом, похожим на истинное местоположение («перцептивное наложение имен»). Мы показываем с реальными примерами, которые отображают уплотнение с использованием нашего метода, могут помочь выявить или избежать таких катастрофических несоответствий».
В будущем новый подход, разработанный этой группой исследователей, может помочь независимо улучшить производительность алгоритмов для приложений VPR без увеличения их вычислительной нагрузки. В результате это также может повысить общую производительность SLAM или систем грубой и точной локализации, которые полагаются на эти модели.
До сих пор Заффар и его коллеги проверяли свой подход, используя простые функции регрессии для интерполяции и экстраполяции дескрипторов, такие как линейная интерполяция и неглубокие нейронные сети, которые учитывали только один или несколько близких эталонных дескрипторов. В своих следующих исследованиях они хотели бы разработать более продвинутые методы интерполяции, основанные на обучении, которые могут учитывать гораздо больше ссылок, поскольку это могло бы еще больше улучшить их подход.
«Например, для запроса, направленного вниз по коридору, ссылка дальше по коридору может предоставить более подробную информацию о том, что должен содержать дескриптор, чем более близкая ссылка, направленная в другом направлении», — добавил Койдж.
«Еще одной целью нашей будущей работы будет предоставление предварительно обученной сети уплотнения карт, которая может обобщать различные позы в различных наборах данных и хорошо работает практически без тонкой настройки. В наших текущих экспериментах мы подгоняем модель с нуля на тренировочном разделение каждого набора данных отдельно. Унифицированная предварительно обученная модель может использовать больше обучающих данных, что позволяет создавать более сложные сетевые архитектуры и давать лучшие готовые результаты для конечных пользователей VPR».