Не секрет, что ChatGPT от OpenAI обладает невероятными возможностями — например, чат-бот может писать стихи, напоминающие шекспировские сонеты, или отлаживать код для компьютерной программы. Эти возможности стали возможными благодаря массивной модели машинного обучения, на которой построен ChatGPT. Исследователи обнаружили, что когда эти типы моделей становятся достаточно большими, появляются экстраординарные возможности.
Но более крупные модели также требуют больше времени и денег для обучения. Процесс обучения включает показ модели сотен миллиардов примеров. Сбор такого количества данных сам по себе является сложным процессом. Затем следуют денежные и экологические затраты , связанные с запуском множества мощных компьютеров в течение нескольких дней или недель для обучения модели, которая может иметь миллиарды параметров.
«Было подсчитано, что модели обучения в масштабе того, на чем, как предполагается, будет работать ChatGPT, могут потребовать миллионы долларов только для одного тренировочного прогона. Можем ли мы повысить эффективность этих методов обучения, чтобы мы по-прежнему могли получать хорошие модели с меньшими затратами?» времени и за меньшие деньги? Мы предлагаем сделать это, используя более мелкие языковые модели, которые ранее были обучены», — говорит Юн Ким, доцент кафедры электротехники и компьютерных наук Массачусетского технологического института и член Лаборатории компьютерных наук и искусственного интеллекта. (ЦСАИЛ).
Вместо того, чтобы отбрасывать предыдущую версию модели, Ким и его сотрудники используют ее в качестве строительных блоков для новой модели. Используя машинное обучение , их метод учит «выращивать» большую модель из меньшей модели таким образом, чтобы кодировать знания, которые меньшая модель уже получила. Это позволяет быстрее обучать более крупную модель.
Их метод экономит около 50% вычислительных затрат, необходимых для обучения большой модели, по сравнению с методами, которые обучают новую модель с нуля. Кроме того, модели, обученные с использованием метода MIT, работали так же или даже лучше, чем модели, обученные с помощью других методов, которые также используют модели меньшего размера для более быстрого обучения более крупных моделей.
Сокращение времени, необходимого для обучения огромных моделей, может помочь исследователям быстрее продвигаться вперед с меньшими затратами, а также сократить выбросы углерода, возникающие в процессе обучения. Это также может позволить небольшим исследовательским группам работать с этими массивными моделями, потенциально открывая двери для многих новых достижений.
«По мере того, как мы стремимся демократизировать эти типы технологий, более важным становится ускорение и удешевление обучения», — говорит Ким, старший автор статьи об этой методике.
Ким и его аспирант Лукас Торроба Хенниген написали статью вместе с ведущим автором Пейхао Ваном, аспирантом Техасского университета в Остине, а также другими сотрудниками лаборатории искусственного интеллекта Watson MIT-IBM и Колумбийского университета. Исследование будет представлено на Международной конференции по обучающим представлениям , которая пройдет с 1 по 5 мая.
Больше лучше
Большие языковые модели, такие как GPT-3, лежащие в основе ChatGPT, построены с использованием архитектуры нейронной сети, называемой преобразователем. Нейронная сеть , основанная на человеческом мозге, состоит из слоев взаимосвязанных узлов или «нейронов». Каждый нейрон содержит параметры, представляющие собой переменные, полученные в процессе обучения, которые нейрон использует для обработки данных.
Архитектуры-трансформеры уникальны, потому что по мере того, как эти типы моделей нейронных сетей становятся больше, они достигают гораздо лучших результатов.
«Это привело к гонке вооружений компаний, пытающихся обучать все более и более крупные преобразователи на все более и более крупных наборах данных. Похоже, что сети-преобразователи становятся намного лучше, чем другие архитектуры, с масштабированием. Мы просто не совсем уверены, почему это так. случае», — говорит Ким.
Эти модели часто имеют сотни миллионов или миллиардов обучаемых параметров. Обучение всех этих параметров с нуля стоит дорого, поэтому исследователи стремятся ускорить процесс.
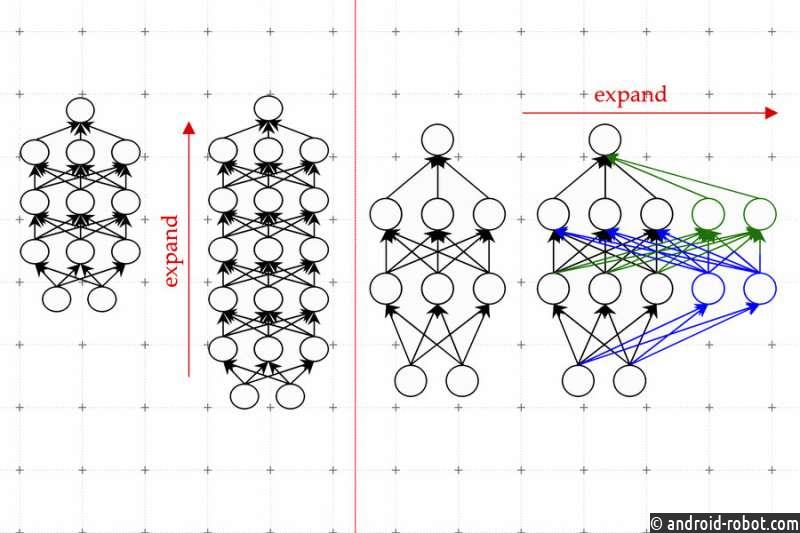
Один из эффективных методов известен как рост модели. Используя метод роста модели, исследователи могут увеличить размер преобразователя, скопировав нейроны или даже целые слои предыдущей версии сети, а затем наложив их сверху. Они могут расширять сеть, добавляя новые нейроны в слой, или углублять ее, добавляя дополнительные слои нейронов.
Ким объясняет, что в отличие от предыдущих подходов к росту модели параметры, связанные с новыми нейронами в расширенном преобразователе, являются не просто копиями параметров меньшей сети. Скорее, это заученные комбинации параметров меньшей модели.
Учимся расти
Ким и его сотрудники используют машинное обучение, чтобы изучить линейное отображение параметров меньшей модели. Эта линейная карта представляет собой математическую операцию, которая преобразует набор входных значений, в данном случае параметры меньшей модели, в набор выходных значений, в данном случае параметры большей модели.
Их метод, который они называют обученным оператором линейного роста (LiGO), учит расширять ширину и глубину более крупной сети за счет параметров меньшей сети на основе данных.
Но меньшая модель на самом деле может быть довольно большой — возможно, она имеет сто миллионов параметров — и исследователи могут захотеть создать модель с миллиардом параметров. Таким образом, метод LiGO разбивает линейную карту на более мелкие части, с которыми может справиться алгоритм машинного обучения.
LiGO также одновременно увеличивает ширину и глубину, что делает его более эффективным, чем другие методы. Ким объясняет, что пользователь может настроить, насколько широкой и глубокой должна быть большая модель, когда он вводит меньшую модель и ее параметры.
Когда они сравнили свою методику с процессом обучения новой модели с нуля, а также с методами роста модели, она оказалась быстрее всех базовых. Их метод экономит около 50 процентов вычислительных затрат, необходимых для обучения как зрительных, так и языковых моделей, часто повышая производительность.
Исследователи также обнаружили, что они могут использовать LiGO для ускорения обучения трансформеров , даже если у них не было доступа к предварительно обученной модели меньшего размера.
«Я был удивлен тем, насколько лучше работают все методы, включая наши, по сравнению со случайной инициализацией и обучением с нуля». — говорит Ким.
В будущем Ким и его сотрудники надеются применить LiGO к еще более крупным моделям.