Глядя на фотографии и опираясь на свой прошлый опыт, люди часто могут ощущать глубину в изображениях, которые сами по себе совершенно плоские. Однако заставить компьютеры делать то же самое оказалось довольно сложно.
Проблема сложна по нескольким причинам, одна из которых заключается в том, что информация неизбежно теряется, когда сцена, происходящая в трех измерениях, сводится к двухмерному (2D) представлению. Существует несколько хорошо зарекомендовавших себя стратегий восстановления 3D-информации из нескольких 2D-изображений, но каждая из них имеет некоторые ограничения. Новый подход под названием «виртуальная переписка», разработанный исследователями Массачусетского технологического института и других институтов, может обойти некоторые из этих недостатков и добиться успеха в тех случаях, когда традиционная методология дает сбои.
Стандартный подход, называемый «структура из движения», основан на ключевом аспекте человеческого зрения . Поскольку наши глаза отделены друг от друга, каждый из них предлагает несколько разные виды объекта. Можно составить треугольник, стороны которого состоят из отрезка, соединяющего два глаза, и отрезка, соединяющего каждый глаз с общей точкой рассматриваемого объекта. Зная углы в треугольнике и расстояние между глазами, можно определить расстояние до этой точки с помощью элементарной геометрии .— хотя человеческая зрительная система, конечно, может делать приблизительные суждения о расстоянии, не прибегая к трудоемким тригонометрическим вычислениям. Эта же основная идея — триангуляции или параллакса — веками использовалась астрономами для расчета расстояния до далеких звезд.
Триангуляция является ключевым элементом структуры движения. Предположим, у вас есть две фотографии объекта — например, скульптурная фигурка кролика — одна сделана с левой стороны фигуры, а другая — с правой. Первым шагом было бы найти точки или пиксели на поверхности кролика, которые являются общими для обоих изображений. Отсюда исследователь мог определить «позы» двух камер — места, откуда были сделаны фотографии, и направление, в котором была обращена каждая камера. Зная расстояние между камерами и то, как они были ориентированы, можно было вычислить расстояние до выбранной точки на кролике с помощью триангуляции. И если будет выявлено достаточно общих точек, можно будет получить подробное представление об общей форме объекта (или «кролика»).
С этой техникой был достигнут значительный прогресс, комментирует Вей-Чиу Ма, доктор философии. студент факультета электротехники и компьютерных наук (EECS) Массачусетского технологического института, «и теперь люди сопоставляют пиксели с большей и большей точностью. Пока мы можем наблюдать одну и ту же точку или точки на разных изображениях, мы можем использовать существующие алгоритмы для определить относительные положения между камерами». Но этот подход работает только в том случае, если два изображения имеют большое перекрытие. Если входные изображения имеют очень разные точки зрения и, следовательно, содержат мало общих точек, если таковые вообще имеются, добавляет он, «система может дать сбой».
Летом 2020 года Ма придумал новый способ ведения дел, который может значительно расширить возможности создания конструкций из движения. Массачусетский технологический институт в то время был закрыт из-за пандемии, и Ма был дома на Тайване, отдыхая на диване. Глядя на свою ладонь и, в частности, на кончики пальцев, ему пришло в голову, что он может ясно представить себе свои ногти, хотя они и не были ему видны.
Это послужило источником вдохновения для идеи виртуальной переписки, которую Ма впоследствии использовал со своим советником Антонио Торральба, профессором EECS и исследователем Лаборатории компьютерных наук и искусственного интеллекта, а также с Анки Джойс Янг и Ракель Уртасун из Университета Торонто. и Шенлонг Ван из Университета Иллинойса. «Мы хотим включить человеческие знания и рассуждения в наши существующие 3D-алгоритмы», — говорит Ма, — те же рассуждения, которые позволили ему смотреть на кончики пальцев и представлять себе ногти с другой стороны — стороны, которую он не мог видеть.
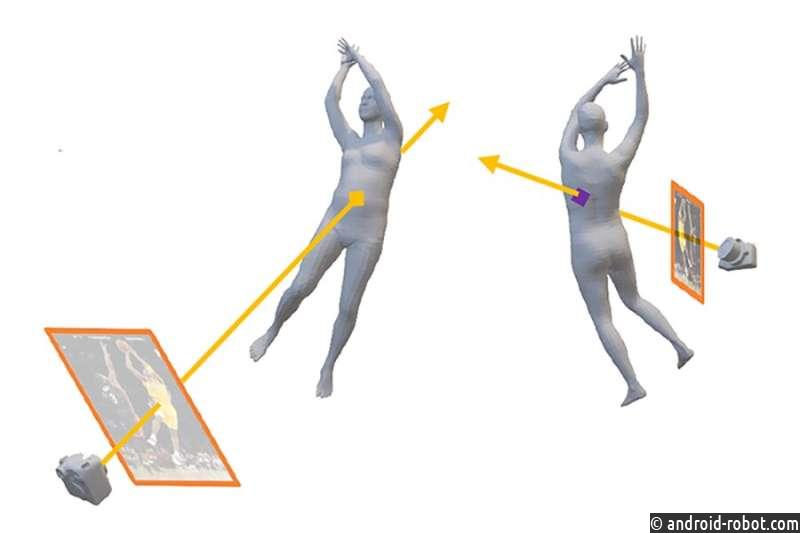
Структура из движения работает, когда два изображения имеют общие точки, потому что это означает, что всегда можно нарисовать треугольник, соединяющий камеры с общей точкой, и, таким образом, из него можно получить информацию о глубине. Виртуальная переписка предлагает способ продвинуться дальше. Предположим еще раз, что одна фотография сделана с левой стороны кролика, а другая — с правой. На первой фотографии может быть видно пятно на левой ноге кролика. Но поскольку свет распространяется по прямой линии, можно было бы использовать общие знания об анатомии кролика, чтобы узнать, где с другой стороны кролика появится световой луч, идущий от камеры к ноге. Эта точка может быть видна на другом изображении (снятом с правой стороны), и если это так, ее можно использовать с помощью триангуляции для вычисления расстояний в третьем измерении.
Иными словами, виртуальное соответствие позволяет взять точку из первого изображения на левом боку кролика и соединить ее с точкой на невидимом правом боку кролика. «Преимущество здесь в том, что для продолжения вам не нужны перекрывающиеся изображения», — отмечает Ма. «Просматривая объект и выходя с другого конца, эта техника дает общие точки для работы, которые изначально не были доступны». Таким образом, можно обойти ограничения, наложенные на традиционный метод.
Можно спросить, сколько предварительных знаний требуется для того, чтобы это работало, потому что, если бы вам нужно было знать форму всего на изображении с самого начала, никаких вычислений не потребовалось бы. Уловка, которую используют Ма и его коллеги, состоит в том, чтобы использовать на изображении определенные знакомые объекты, например человеческую форму, в качестве своего рода «якоря». Они разработали методы использования наших знаний о человеческой форме, чтобы помочь определить позы камеры и, в некоторых случаях, сделать вывод о глубине изображения. Кроме того, объясняет Ма, «предварительные знания и здравый смысл, встроенные в наши алгоритмы, сначала фиксируются и кодируются нейронными сетями».
По словам Ма, конечная цель команды гораздо более амбициозна. «Мы хотим создать компьютеры, которые смогут понимать трехмерный мир так же, как это делают люди». Он признает, что эта цель еще далека от реализации. «Но чтобы выйти за пределы того, что мы имеем сегодня, и построить систему, которая действует как люди, нам нужны более сложные условия. Другими словами, нам нужно разработать компьютеры, которые могут не только интерпретировать неподвижные изображения, но также могут понимать короткие видеоклипы и в конце концов, полнометражные фильмы».
Сцена в фильме «Умница Уилл Хантинг» демонстрирует, что он имеет в виду. Зрители видят сзади Мэтта Деймона и Робина Уильямса, сидящих на скамейке с видом на пруд в общественном саду Бостона. Следующий кадр, сделанный с противоположной стороны, предлагает фронтальные (хотя и полностью одетые) виды Деймона и Уильямса на совершенно другом фоне. Каждый, кто смотрит фильм, сразу понимает, что видит одних и тех же двух людей, хотя у этих двух кадров нет ничего общего. Компьютеры пока не могут совершить такой концептуальный скачок, но Ма и его коллеги усердно работают над тем, чтобы сделать эти машины более совершенными и — по крайней мере, когда дело доходит до зрения — более похожими на нас.
Работа команды будет представлена на следующей неделе на конференции по компьютерному зрению и распознаванию образов.