Исследователи Корнельского университета разработали интерфейс распознавания тихой речи, который использует акустическое восприятие и искусственный интеллект для непрерывного распознавания до 31 невокализованной команды на основе движений губ и рта.
Маломощному носимому интерфейсу под названием EchoSpeech требуется всего несколько минут данных для обучения пользователя, прежде чем он распознает команды и сможет работать на смартфоне.
Жуйдун Чжан, докторант информационных наук, является ведущим автором книги «EchoSpeech: непрерывное распознавание тихой речи в минимально навязчивых очках на основе акустического восприятия», которая будет представлена на конференции Ассоциации вычислительной техники, посвященной человеческому фактору в вычислительных системах ( CHI) в этом месяце в Гамбурге, Германия.
«Для людей, которые не могут озвучивать звук, эта технология безмолвной речи может стать отличным входом для голосового синтезатора. Она может вернуть пациентам их голос», — сказал Чжан о потенциальном использовании технологии при дальнейшем развитии.
В своем нынешнем виде EchoSpeech можно использовать для общения с другими через смартфон в местах, где речь неудобна или неуместна, например, в шумном ресторане или тихой библиотеке. Бесшумный речевой интерфейс также можно использовать в паре со стилусом и использовать с программным обеспечением для проектирования, таким как САПР, практически исключая необходимость в клавиатуре и мыши.
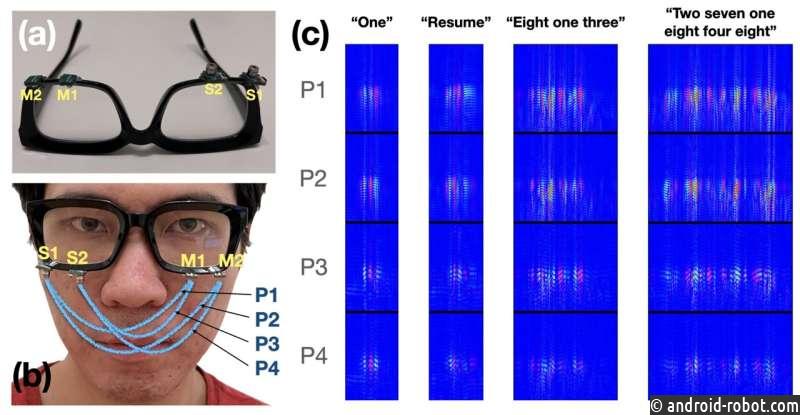
Оснащенные парой микрофонов и динамиками меньшего размера, чем ластик для карандашей, очки EchoSpeech превращаются в носимую гидролокационную систему с искусственным интеллектом , отправляющую и принимающую звуковые волны по лицу и воспринимающую движения рта. Затем алгоритм глубокого обучения анализирует эти эхо-профили в режиме реального времени с точностью около 95%.
«Мы перемещаем сонар на тело», — сказал Ченг Чжан, доцент кафедры информатики и директор лаборатории интеллектуальных компьютерных интерфейсов для будущих взаимодействий (SciFi) Корнелла.
«Мы очень рады этой системе, — сказал он, — потому что она действительно продвигает вперед области производительности и конфиденциальности . реальный мир.»
По словам Чэн Чжан, большинство технологий распознавания немой речи ограничены набором предопределенных команд и требуют, чтобы пользователь смотрел в камеру или носил ее, что нецелесообразно и невыполнимо. По его словам, существуют также серьезные проблемы с конфиденциальностью, связанные с носимыми камерами — как для пользователя, так и для тех, с кем он взаимодействует.
Технология акустического восприятия, такая как EchoSpeech, устраняет необходимость в носимых видеокамерах. А поскольку аудиоданные намного меньше, чем изображения или видеоданные, для их обработки требуется меньшая полоса пропускания, и их можно передавать на смартфон через Bluetooth в режиме реального времени, говорит профессор информатики Франсуа Гимбретьер .
«А поскольку данные обрабатываются локально на вашем смартфоне, а не загружаются в облако, — сказал он, — конфиденциальная информация никогда не выходит из-под вашего контроля».