Методы объяснения, которые помогают пользователям понять модели машинного обучения и доверять им, часто описывают, насколько определенные функции, используемые в модели, способствуют ее предсказанию. Например, если модель предсказывает риск развития сердечного заболевания у пациента, врач может захотеть узнать, насколько сильно на этот прогноз влияют данные о частоте сердечных сокращений пациента.
Но если эти функции настолько сложны или запутаны, что пользователь не может их понять, поможет ли метод объяснения?
Исследователи Массачусетского технологического института стремятся улучшить интерпретируемость функций, чтобы лицам, принимающим решения , было удобнее использовать результаты моделей машинного обучения . Опираясь на годы полевой работы, они разработали таксономию, чтобы помочь разработчикам создавать функции, которые будет легче понять их целевой аудитории.
«Мы обнаружили, что в реальном мире, несмотря на то, что мы использовали самые современные способы объяснения моделей машинного обучения, все еще остается много путаницы, связанной с функциями, а не с самой моделью», — говорит Александра Зитек, кандидат электротехники и компьютерных наук. студент и ведущий автор статьи, представляющей таксономию.
Чтобы построить таксономию, исследователи определили свойства, которые делают функции интерпретируемыми для пяти типов пользователей, от экспертов по искусственному интеллекту до людей, затронутых прогнозом модели машинного обучения. Они также предлагают инструкции о том, как создатели моделей могут преобразовывать функции в форматы, которые будет легче понять непрофессионалу.
Они надеются, что их работа вдохновит разработчиков моделей на использование интерпретируемых функций с самого начала процесса разработки, вместо того, чтобы пытаться работать в обратном направлении и сосредотачиваться на объяснимости постфактум.
Среди соавторов Массачусетского технологического института Донгю Лю, постдок; приглашенный профессор Лор Берти-Экиль, директор по исследованиям IRD; и старший автор Кальян Верамачанени, главный научный сотрудник Лаборатории систем информации и принятия решений (LIDS) и руководитель группы Data to AI. К ним присоединяется Игнасио Арнальдо, главный специалист по данным в Corelight. Исследование опубликовано в июньском выпуске рецензируемого информационного бюллетеня Explorations Newsletter Ассоциации вычислительной техники.
Уроки реального мира
Функции — это входные переменные, которые передаются в модели машинного обучения; они обычно берутся из столбцов в наборе данных. Специалисты по обработке и анализу данных обычно выбирают и обрабатывают функции для модели, и они в основном сосредоточены на обеспечении того, чтобы функции были разработаны для повышения точности модели, а не на том, может ли лицо, принимающее решения, понять их, объясняет Верамачанени.
В течение нескольких лет он и его команда работали с лицами, принимающими решения, над выявлением проблем юзабилити машинного обучения. Эти эксперты в предметной области, большинству из которых не хватает знаний в области машинного обучения, часто не доверяют моделям, потому что не понимают особенностей, влияющих на прогнозы.
В рамках одного проекта они сотрудничали с клиницистами в отделении интенсивной терапии больницы, которые использовали машинное обучение для прогнозирования риска осложнений после операции на сердце. Некоторые функции были представлены в виде агрегированных значений, таких как динамика частоты сердечных сокращений пациента с течением времени. Хотя функции, закодированные таким образом, были «готовы к модели» (модель могла обрабатывать данные), клиницисты не понимали, как они вычислялись. По словам Лю, они предпочли бы увидеть, как эти агрегированные характеристики соотносятся с исходными значениями, чтобы выявить аномалии в частоте сердечных сокращений пациента.
Напротив, группа обучающихся ученых предпочла агрегированные признаки. Вместо такой функции, как «количество сообщений, сделанных студентом на дискуссионных форумах», они предпочли бы, чтобы связанные функции были сгруппированы вместе и помечены понятными им терминами, такими как «участие».
«Что касается интерпретируемости, один размер не подходит для всех. Когда вы переходите от области к области, возникают разные потребности. И сама интерпретируемость имеет много уровней», — говорит Верамачанени.
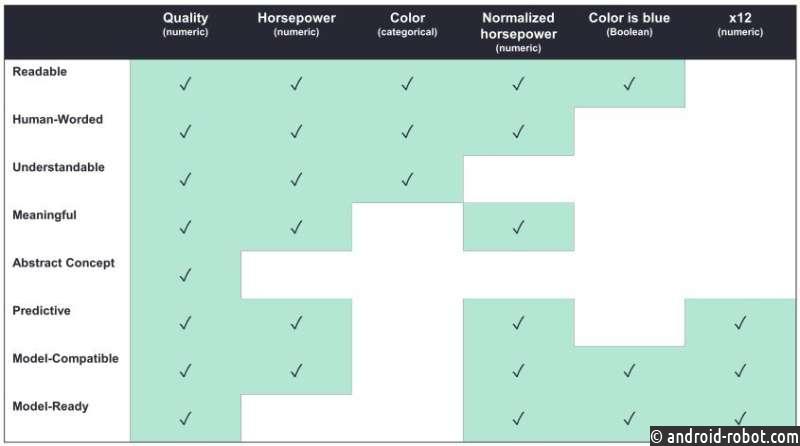
Идея о том, что один размер не подходит всем, является ключом к таксономии исследователей. Они определяют свойства, которые могут сделать функции более или менее интерпретируемыми для разных лиц, принимающих решения, и определяют, какие свойства наиболее важны для конкретных пользователей.
Например, разработчики машинного обучения могут сосредоточиться на наличии функций, совместимых с моделью и прогнозирующих, то есть ожидается, что они улучшат производительность модели.
С другой стороны, лица, принимающие решения, не имеющие опыта машинного обучения, могут лучше обслуживаться функциями, сформулированными человеком, то есть они описаны естественным для пользователей и понятным образом, то есть они относятся к реальным пользователям показателей. может рассуждать о.
«Таксономия говорит, если вы создаете интерпретируемые функции, до какого уровня они интерпретируются? Вам могут не понадобиться все уровни, в зависимости от типа экспертов в предметной области, с которыми вы работаете», — говорит Зитек.
Ставим интерпретируемость на первое место
Исследователи также описывают методы разработки функций, которые разработчик может использовать, чтобы сделать функции более интерпретируемыми для конкретной аудитории.
Разработка признаков — это процесс, в котором специалисты по данным преобразуют данные в формат, который могут обрабатывать модели машинного обучения, используя такие методы, как агрегирование данных или нормализация значений. Большинство моделей также не могут обрабатывать категориальные данные, если они не преобразованы в числовой код. Эти преобразования часто почти невозможно расшифровать для неспециалистов.
Zytek говорит, что создание интерпретируемых функций может потребовать отмены некоторых из этих кодировок. Например, общий метод проектирования признаков организует диапазоны данных так, чтобы все они содержали одинаковое количество лет. Чтобы сделать эти функции более интерпретируемыми, можно сгруппировать возрастные диапазоны, используя человеческие термины, такие как младенец, малыш, ребенок и подросток. Или вместо использования преобразованной функции, такой как средняя частота пульса, интерпретируемой функцией могут быть просто данные о фактической частоте пульса, добавляет Лю.
«Во многих областях компромисс между интерпретируемыми функциями и точностью модели на самом деле очень мал. Например, когда мы работали со средствами проверки благополучия детей, мы переобучали модель, используя только те функции, которые соответствовали нашим определениям интерпретируемости, и производительность снизилась. был почти незначителен», — говорит Зитек.
Основываясь на этой работе, исследователи разрабатывают систему, которая позволяет разработчику модели более эффективно обрабатывать сложные преобразования функций, чтобы создавать ориентированные на человека объяснения для моделей машинного обучения . Эта новая система также преобразует алгоритмы, предназначенные для объяснения готовых к моделированию наборов данных, в форматы, понятные лицам, принимающим решения.