Достижения в области биологических изображений предоставили ученым беспрецедентные наборы данных с чрезвычайно высоким разрешением, но инструменты интерпретации данных работают сверхурочно, чтобы не отставать. Это особенно очевидно в случае криоэлектронных томограмм (крио-ЭТ), где образцы имеют изначально низкую контрастность из-за ограниченной дозы электронов, которые могут быть применены во время визуализации до того, как произойдет радиационное повреждение.
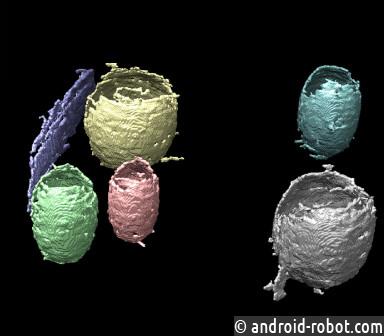
Сегментация этих клеточных томограмм остается сложной задачей, которая наиболее точно выполняется людьми с большим количеством свободного времени. Поскольку интерпретировать большие наборы данных таким способом невозможно, группа ученых из лаборатории Беркли недавно разработала и протестировала несколько методов машинного обучения, организованных в конвейер обучения для сегментации и идентификации структур клеточных мембран крио-ЭТ. В этом месяце в Journal of Computational Science была опубликована статья с описанием их подхода «Конвейер машинного обучения для мембранной сегментации криоэлектронных томограмм».
«Одна из основных трудностей с этими типами изображений заключается в том, что они очень шумные», — сказал Чао Ян, старший научный сотрудник отдела прикладной математики и вычислительных исследований Национальной лаборатории Лоуренса в Беркли (Berkeley Lab) и один из авторов статьи. . «Это главная проблема, когда вы пытаетесь обнаружить какой-либо тип структуры или сегментировать изображения — одному ученому может потребоваться несколько месяцев, чтобы правильно сегментировать одну томограмму».
Хотя за последние несколько десятилетий был разработан ряд алгоритмов и инструментов автоматизированной сегментации для высококонтрастной медицинской 3D-визуализации, большинство из них плохо работают на крио-ЭТ, поскольку наборы данных имеют низкое отношение сигнал/шум, а также отсутствующие данные. клиновидные артефакты, вызванные ограниченным диапазоном наклона образца, доступным во время визуализации. Учитывая сложность задачи сегментации и неотъемлемую проблему получения высококачественных томограмм, исследователи знали, что маловероятно, что одна технология обработки изображений или машинного обучения даст удовлетворительные результаты, поэтому они приступили к разработке конвейера анализа изображений и сегментации. который сочетал в себе различные методы.
Этот проект финансировался LDRD (Программа направленных исследований и разработок в лаборатории) в сотрудничестве с учеными Ником Сотером и Карен Дэвис из отдела молекулярной биофизики и интегрированной биовизуализации (MBIB) лаборатории Беркли. Команда использовала суперкомпьютер Cori в Национальном научно-исследовательском вычислительном центре энергетических исследований (NERSC) в лаборатории Беркли для проверки своих методов и дальнейшего совершенствования подхода к трубопроводу.
«Уже существует множество существующих алгоритмов машинного обучения, в основном связанных с медицинской визуализацией, но когда вы пытаетесь применить их к крио-ЭТ, они просто не работают, в основном из-за низкого отношения сигнал/шум. — сказала Талита Перчиано, научный сотрудник отдела научных данных лаборатории Беркли и еще один соавтор статьи. «В последнее время было много разработок в области использования сверточных нейронных сетей (CNN) для решения подобных задач сегментации изображений, поэтому мы изучили эти исследования, опробовали их и обнаружили, что можем получить довольно хорошую сегментацию, но не идеальную. Поэтому мы знали, что должны использовать и другие методы машинного обучения».
Многосторонний подход
Исследовательская группа знала, что ученый-человек может гораздо лучше, чем компьютерная программа, выполнять работу по сегментации и извлечению мембранных структур, потому что у ученого есть предварительные знания о биологическом объекте, который нужно сегментировать, поэтому они включили эту идею в свой процесс с помощью нескольких методов машинного обучения. методы:
- Они объединили несколько методов машинного обучения, чтобы улучшить результаты сегментации, полученные с помощью процедуры на основе CNN. Они использовали популярный инструмент сегментации на основе CNN, U-Net, который идентифицирует мембранные структуры в соответствии с геометрическими мотивами, используемыми в обучающих данных из срезов томограммы.
- Они использовали алгоритмы обучения с подкреплением, чтобы соединить несколько сегментированных частей, принадлежащих одной мембранной структуре.
- Они применили алгоритмы классификации, чтобы разделить различные мембранные структуры и поместить фрагменты одной и той же структуры в одну группу.
- Они использовали алгоритмы параметрической и непараметрической подгонки для получения гладкого и непрерывного представления поверхности мембран.
«Нейронные сети оставляют пробелы в определенных областях, поэтому мы использовали обучение с подкреплением, чтобы отследить, как может выглядеть контур, а затем объединили это с методами машинного обучения на основе гауссовского процесса, чтобы немного сгладить поверхность», — сказал Чао. «С этой системой, которую мы разработали, мы планируем перейти от этого процесса, занимающего месяцы с настоящими биологами-людьми, к тому, что займет недели, возможно, даже дни».
Биологическое воздействие этого типа системы машинного обучения — это гораздо более широкое понимание того, как различные клеточные структуры поддерживают ее функции. «Если бы это была всего одна клетка, мы могли бы сделать это вручную, но реальный потенциал заключается в том, чтобы увидеть одну и ту же клеточную структуру на протяжении всего жизненного цикла организма и то, как она меняется в различных условиях окружающей среды и внешних раздражителях», — сказал Сотер. , старший научный сотрудник MBIB, соавтор статьи. «С большими данными новые методы машинного обучения могут помочь выяснить, как разнообразный ансамбль структур поддерживает функцию в клетке».
По словам Перчиано, объединив различные методы, исследователи смогли разработать систему, которая требует меньше времени и дает лучший результат. Этот подход хорошо себя зарекомендовал для сегментации поверхностей мембран в двух больших наборах биологических данных, и, учитывая его гибкость, его можно применять к различным наборам данных с минимальными изменениями.
«Крио-ЭМ и томография в последнее десятилетие получили широкое распространение, поэтому ученые получают множество структур, но эти структуры необходимо интерпретировать», — сказал Чао. «Итак, теперь задача заключается именно в этом, и если инструменты машинного обучения помогут ускорить этот процесс, это окажет большое влияние на биологические исследования».