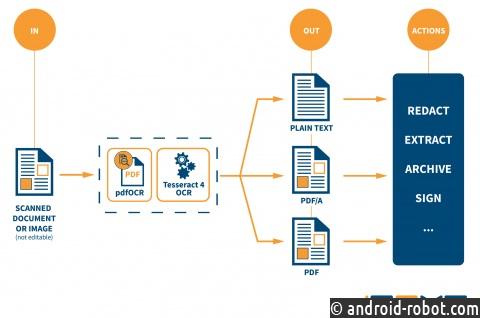
Программное обеспечение компании iText Group NV, известного в мире новатора и лидера в сфере разработки решений для работы с PDF-файлами, получило мощное дополнение с открытым исходным кодом iText pdfOCR. Продукт, выпускаемый на рынок, дает возможность распознавать в отсканированных документах текст и конвертировать его в редактируемые PDF-файлы.
Приложение iText pdfOCR – часть популярного пакета iText 7 PDF SDK – имеет функцию оптического распознавания символов. С ее помощью можно печатный текст в отсканированных документах и изображениях конвертировать в документ формата PDF/A-3u с поддержкой полнотекстового поиска (PDF, версия 1.7). Работа с такими текстами становится быстрее и проще. Отсутствие машиночитаемого текста в отсканированных или печатных документах препятствует поиску, индексированию или переводу таких документов. Распознавание текста с помощью iText pdfOCR открывается возможность извлечения данных из документа посредством дополнения iText pdf2Data, безопасно его отредактировать его содержимое, воспользовавшись iText pdfSweep или воссоздать многоязычные документы с помощью iText pdfCalligraph. Завершающим штрихом в работе с документом станет использование генератора низкоуровневых кодов iText DITO® для видоизменения данных.
Презентация приложения iText pdfOCR состоится в прямом эфире 9 июля 2020 года. По словам вице-президента отдела маркетинга и продукции компании iText Group NV и гендиректора iText Software Belgium Тони Ван ден Зегеля, новый продукт расширяет возможности цифрового рабочего процесса.