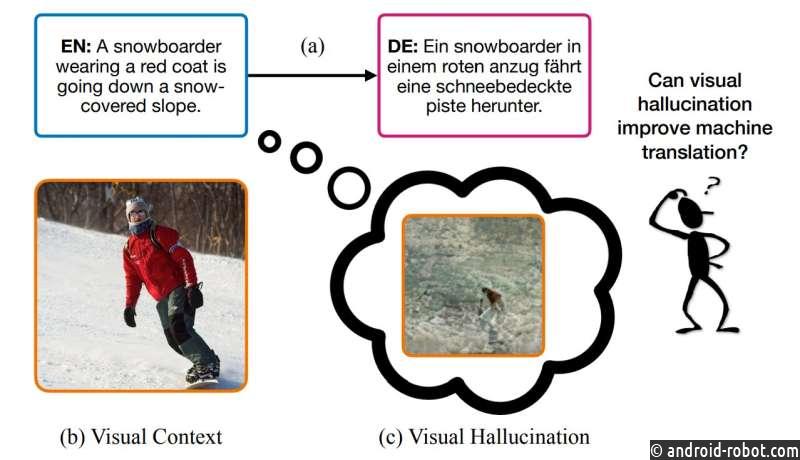
В младенчестве мы лепечем и имитируем наш способ изучения языков. Мы не начинаем с чтения необработанного текста, что требует фундаментальных знаний и понимания мира, а также продвинутой способности интерпретировать и делать выводы о описаниях и отношениях. Скорее, люди начинают наше языковое путешествие медленно, указывая на окружающую среду и взаимодействуя с ней, основывая наши слова и воспринимая их значение через контекст физического и социального мира. В конце концов, мы можем составлять полные предложения для передачи сложных идей.
Точно так же, когда люди начинают изучать и переводить на другой язык, включение другой сенсорной информации, такой как мультимедиа, в сочетании с новыми и незнакомыми словами, такими как карточки с изображениями, улучшает усвоение и запоминание языка. Затем, при достаточной практике, люди смогут точно переводить новые, невидимые предложения в контексте без сопутствующих медиа; однако помогает представление картинки на основе исходного текста.
Это основа новой модели машинного обучения под названием VALHALLA, разработанной исследователями из Массачусетского технологического института, IBM и Калифорнийского университета в Сан-Диего, в которой обученная нейронная сеть видит исходное предложение на одном языке, галлюцинирует образ того, что оно выглядит так, а затем использует оба для перевода на целевой язык. Команда обнаружила, что их метод демонстрирует более высокую точность машинного перевода по сравнению с переводом только текста. Кроме того, это дало дополнительный импульс для случаев с длинными предложениями, языками с ограниченными ресурсами и случаями, когда часть исходного предложения недоступна для машинного переводчика.
Как основная задача в области обработки естественного языка (NLP) ИИ, машинный перевод — это «чрезвычайно практичная технология, которую используют миллионы людей каждый день», — говорит соавтор исследования Юн Ким, доцент кафедры электротехники Массачусетского технологического института. Инженерные и компьютерные науки с филиалами в Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) и Лаборатории искусственного интеллекта Watson MIT-IBM. С недавними значительными достижениями в области глубокого обучения «было интересное развитие в том, как можно использовать нетекстовую информацию — например, изображения, аудио или другую базовую информацию — для решения практических задач, связанных с языком», — говорит Ким, потому что « когда люди выполняют задачи по обработке речи, мы делаем это в заземленном, ситуативном мире».
Это исследование будет представлено на конференции IEEE/CVF по компьютерному зрению и распознаванию образов в этом месяце. Соавторами Кима являются аспирант Калифорнийского университета в Сан-Диего Йи Ли и профессор Нуно Васконселос, а также научные сотрудники Рамесвар Панда, Чун-фу «Ричард» Чен, Роджерио Ферис и директор IBM Дэвид Кокс из IBM Research и MIT-IBM Watson. Лаборатория искусственного интеллекта.
Учимся галлюцинировать по изображениям
Когда мы изучаем новые языки и переводим, нам часто предоставляют примеры и практику, прежде чем мы начнем действовать самостоятельно. То же самое верно и для систем машинного перевода; однако, если изображения используются во время обучения, эти методы ИИ также требуют визуальных средств для тестирования, что ограничивает их применимость, говорит Панда.
«В реальных сценариях у вас может не быть изображения по отношению к исходному предложению. Таким образом, наша мотивация была в основном: вместо использования внешнего изображения во время вывода в качестве входных данных, можем ли мы использовать визуальную галлюцинацию — способность представлять визуальные сцены. — улучшить системы машинного перевода?» говорит Панда.
Для этого команда использовала архитектуру кодер-декодер с двумя преобразователями, тип модели нейронной сети , который подходит для данных, зависящих от последовательности, таких как язык, который может обращать внимание на ключевые слова и семантику предложения. Один преобразователь генерирует визуальную галлюцинацию, а другой выполняет мультимодальную трансляцию, используя выходы первого преобразователя.
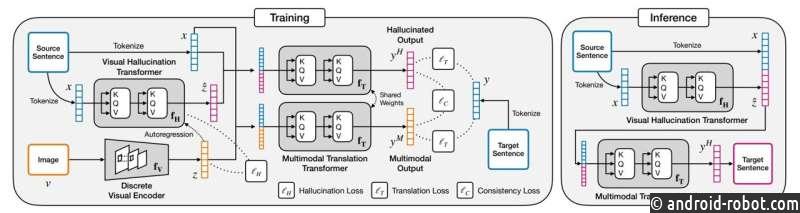
Во время обучения есть два потока перевода: исходное предложение и репрезентативное изображение, которое с ним связано, и то же самое исходное предложение, которое зрительно галлюцинирует, чтобы создать пару текст-изображение. Сначала истинное изображение и предложение преобразуются в представления, которые могут обрабатываться преобразователями; в случае предложения каждое слово является токеном. Исходное предложение снова токенизируется, но на этот раз проходит через преобразователь визуальных галлюцинаций, выводя галлюцинацию, дискретное образное представление предложения. Исследователи внедрили авторегрессию, которая сравнивает реальные и галлюцинированные представления на соответствие — например, омонимы: ссылка на животное «летучая мышь» не галлюцинируется как бейсбольная бита.
Затем два набора токенов одновременно проходят через мультимодальный преобразователь перевода, каждый из которых содержит представление предложения и либо галлюцинаторный, либо реальный образ. Токенизированные результаты перевода текста сравниваются с целью их сходства друг с другом и с целевым предложением на другом языке . Любые различия затем передаются обратно в преобразователь трансляции для дальнейшей оптимизации.
Для тестирования поток реальных изображений падает, поскольку изображения, вероятно, не будут доступны в повседневных сценариях.
«Насколько нам известно, мы не видели ни одной работы, в которой на самом деле использовался бы преобразователь галлюцинаций совместно с мультимодальной системой перевода для повышения производительности машинного перевода», — говорит Панда.
Визуализация целевого текста
Чтобы проверить свой метод, команда сравнила VALHALLA с другими современными мультимодальными и текстовыми методами перевода. Они использовали общедоступные эталонные наборы данных, содержащие достоверные изображения с исходными предложениями, и набор данных для перевода новостных статей, состоящих только из текста. Исследователи измерили его производительность по 13 задачам, начиная от перевода на языки с хорошими ресурсами (например, английский, немецкий и французский), языки с ограниченными ресурсами (например, с английского на румынский) и неанглийский (например, с испанского на французский). Группа также проверила различные размеры моделей трансформеров, то, как точность меняется в зависимости от длины предложения, и перевод в ограниченном текстовом контексте, когда части текста были скрыты от машинных переводчиков.
Команда заметила значительные улучшения по сравнению с методами перевода только текста, повышение эффективности данных и то, что меньшие модели работают лучше, чем большая базовая модель. По мере того, как предложения становились длиннее, эффективность VALHALLA по сравнению с другими методами росла, что исследователи объясняли добавлением более двусмысленных слов. В тех случаях, когда часть предложения была замаскирована, VALHALLA могла восстановить и перевести исходный текст, что команда нашла удивительным.
Возникли и другие неожиданные результаты: «Там, где было не так много обучающих пар [изображение и] текст, [например, для языков с ограниченными ресурсами], улучшения были более значительными, что указывает на то, что использование изображений помогает в режимах с низким объемом данных», — говорит Ким. «Еще одна вещь, которая меня весьма удивила, — это улучшенная производительность даже для типов текста, которые не обязательно легко соединить с изображениями. Например, может быть, это не так уж удивительно, если это помогает переводить визуально выделяющиеся предложения, такие как «там». стоит красная машина перед домом». [Однако] даже в текстовых доменах [новостных статей] этот подход смог улучшить текстовые системы».
Хотя VALHALLA работает хорошо, исследователи отмечают, что у нее есть ограничения, требующие, чтобы пары предложений были аннотированы изображением, что может сделать ее получение более дорогим. Он также лучше работает в своей основной области, а не только в текстовых новостных статьях. Более того, отмечают Ким и Панда, такая техника, как VALHALLA, по-прежнему остается «черным ящиком» с предположением, что галлюцинации предоставляют полезную информацию, и команда планирует исследовать, что и как изучает модель, чтобы проверить свои методы.
В будущем команда планирует изучить другие способы улучшения перевода. «Здесь мы фокусируемся только на изображениях, но есть и другие типы мультимодальной информации — например, речь, видео, прикосновение или другие сенсорные модальности», — говорит Панда. «Мы считаем, что такая мультимодальная основа может привести к еще более эффективным моделям машинного перевода, что потенциально принесет пользу переводу на многие малоресурсные языки, на которых говорят в мире».